
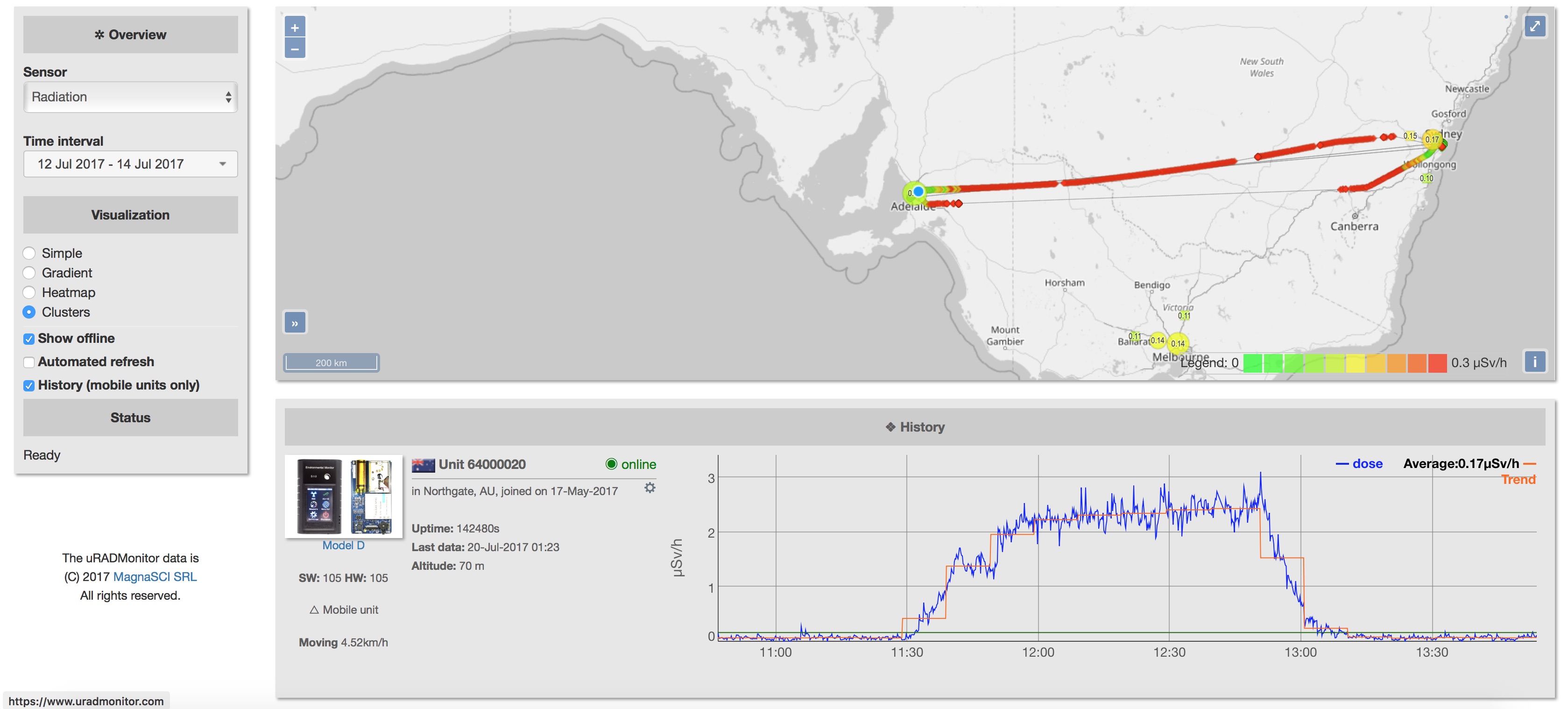
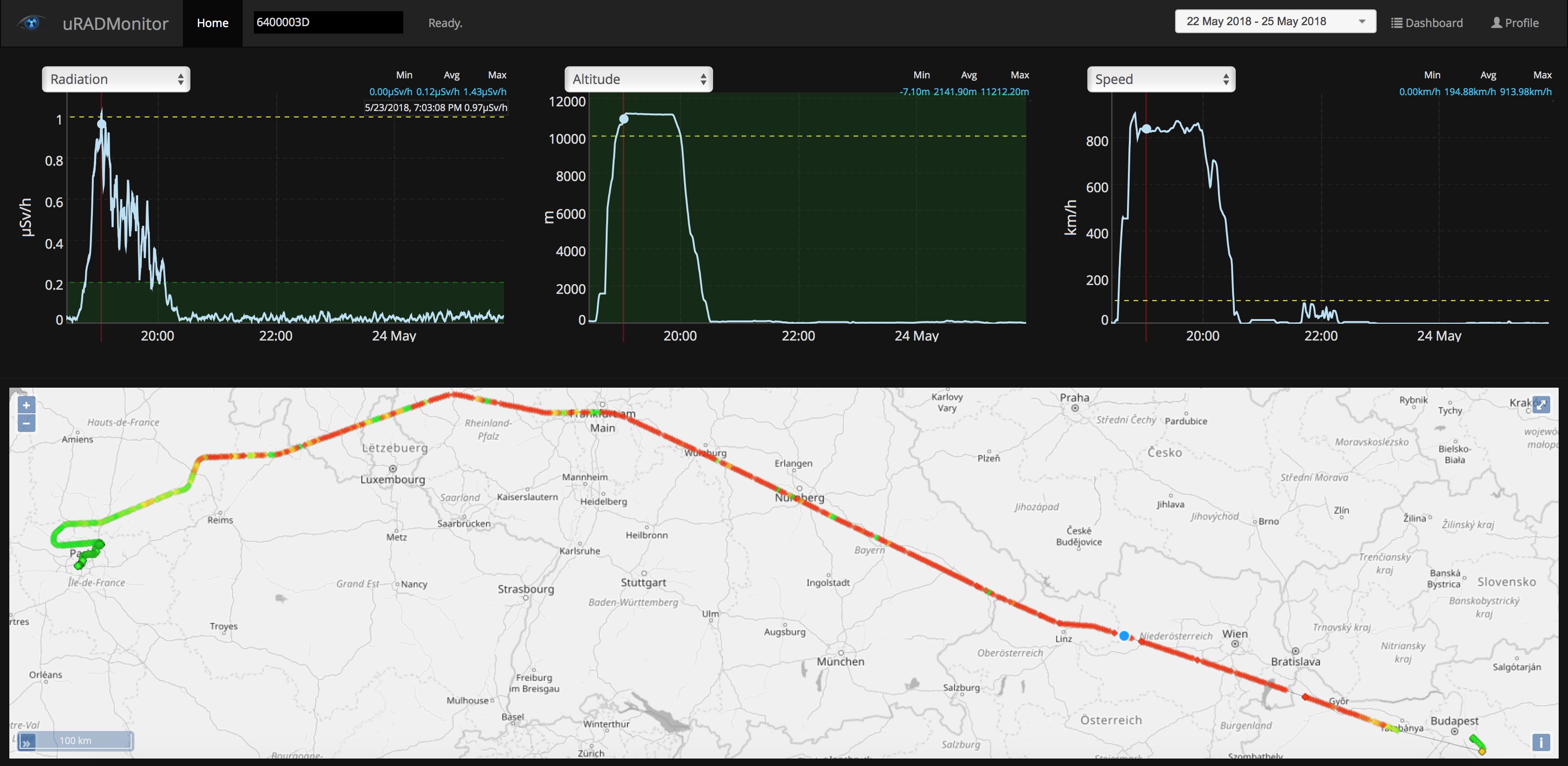
A few years back I wrote a NMEA parser library that would run on AVR Microcontrollers. Released as open source under GPL, it became quite popular. All these years I used this code as reliable way to add GPS functionality to my hardware projects. One example is the portable environmental monitor, the “model D”, here’s some cosmic radiation data mapped to location in an airplane flight, that was created using this code:
The code previously worked by taking a NMEA sentence and splitting it into words. Then each work is interpreted and data extracted:
char tmp_words[20][18], // hold parsed words for one given NMEA sentence
/* $GPGGA
* $GPGGA,hhmmss.ss,llll.ll,a,yyyyy.yy,a,x,xx,x.x,x.x,M,x.x,M,x.x,xxxx*hh
* ex: $GPGGA,230600.501,4543.8895,N,02112.7238,E,1,03,3.3,96.7,M,39.0,M,,0000*6A,
*
* WORDS:
* 1 = UTC of Position
* 2 = Latitude
* 3 = N or S
* 4 = Longitude
* 5 = E or W
* 6 = GPS quality indicator (0=invalid; 1=GPS fix; 2=Diff. GPS fix)
* 7 = Number of satellites in use [not those in view]
* 8 = Horizontal dilution of position
* 9 = Antenna altitude above/below mean sea level (geoid)
* 10 = Meters (Antenna height unit)
* 11 = Geoidal separation (Diff. between WGS-84 earth ellipsoid and mean sea level.
* -geoid is below WGS-84 ellipsoid)
* 12 = Meters (Units of geoidal separation)
* 13 = Age in seconds since last update from diff. reference station
* 14 = Diff. reference station ID#
* 15 = Checksum
*/ The code was shaped so it would work with UART interrupts, building on the characters received via the UART ISR and grouping them in words based on the various separators. You can see the previous code here.
This needed considerable memory to store all the words in the sentence, something we don’t have on a small microcontroller. Just the structure tmp_words needed 20×18 = 360 bytes of memory! Just think of the atmega328p that only has 2KB. But we don’t really need to store ALL the words at the same time, we just need to extract each NMEA word and interpret its meaning / value.
So I had to do an update, also due to some issues I ran into with a project I’ve been working on, where large chunks of incoming data on a non-flushed serial line switched by a multiplexer would cause buffer overflows that only become obvious after a few hours. The major change was to store one NMEA line in memory, compute its checksum, then parse it for words.
struct _gpsData {
uint8_t hour, min, sec, // UTC Time
fix, // GPS quality indicator (0=invalid; 1=GPS fix; 2=Diff. GPS fix)
sats, // sats in view
day, month, year,
checksum,
ready;
double latitude, longitude, altitude, speed;
} gpsD;
int fusedata(char c) {
buf[bufIndex] = c;
if (bufIndex == 0 && c != '$') {
bufIndex = 0; return 0;
}
if (c == '*') starIndex = bufIndex;
if (c== '\r') {
if (strstr((char*)buf, "$GPGGA")) parsedata(1);
if (strstr((char*)buf, "$GPRMC")) parsedata(2);
}
bufIndex ++;
if (bufIndex == MAX_BUFFER - 1) bufIndex = 0; // start over
return bufIndex;
}See the entire code here:
Update
The version above does bring some improvements, but one caveat might be the use of the buffer that holds the entire NMEA sentence. We don’t really need to do that, instead we can interpret words individually and populate our GPS data structure, while at the end, when the sentence is fully parse we can simply check the checksum and mark data as OK or discard it all together. Dropping the buffer saves some memory and this is a good thing especially on embedded systems.
The “fusedata” function that receives one character at a time (over a serial line) becomes:
int fusedata(char c) {
// compute checksum
if (c == '*') star = 1;
if (c!= '$' && !star) {
checksum ^= c; // compute checksum on all chars between $ and *
}
// start word
if (c == '$') {
ci = 0;
wi = 0; // start word count
gga = 0; // is this a GGA? (more sentences can be added)
rmc = 0; // is this a RMC?
ready = 0; // sentence is not ready
checksum = 0; // checksum will go here
star = 0; // did we hit star?
}
// end word
else if (c == ',' || c == '*' || c == '\r' || ci == MAX_WORD - 1) {
word[ci] = 0;
if (wi == 0 && mstrncmp((char*)word, "$GPGGA", 6) == 0) gga = 1;
if (wi == 0 && mstrncmp((char*)word, "$GPRMC", 6) == 0) rmc = 1;
// parse word
parsedata();
wi ++ ; // we have a new word
ci = 0;
return 0;
}
// build word
word[ci++] = c;
}You can see we need no buffer now, but instead we form the words in “word” and parse them right away.
